Bringing Software Engineering Discipline to Data: Our dbt + Snowflake CI/CD
Discover how to implement software engineering best practices in data engineering using dbt and Snowflake. Learn about CI/CD pipelines, version control, testing, and deployment strategies that ensure reliable, scalable data transformations.
Bringing Software Engineering Discipline to Data: Our dbt + Snowflake CI/CD
Data engineering has evolved dramatically in 2025. Organizations are now applying the same rigorous software engineering practices to data pipelines that they've used for application development for decades. This transformation is revolutionizing how we build, test, and deploy data transformations at scale.
The Evolution of Data Engineering
Traditional data engineering often resembled the "wild west" of software development:
- Manual processes with limited version control
- Ad-hoc testing or no testing at all
- Deployment chaos with unclear rollback procedures
- Siloed knowledge trapped in individual scripts
Modern data engineering in 2025 embraces DataOps principles:
- Version-controlled transformations with complete audit trails
- Automated testing at multiple levels
- Continuous integration with automated quality gates
- Reproducible deployments across environments
Why dbt + Snowflake for Modern Data Engineering
The Perfect Partnership
| Component | Role | Key Benefits |
|---|---|---|
| dbt (Data Build Tool) | Transformation layer | Version control, testing, documentation |
| Snowflake | Data warehouse | Scalability, performance, separation of compute/storage |
| CI/CD Pipeline | Automation layer | Quality gates, automated deployments, rollback capabilities |
dbt: Transforming Data Engineering
dbt brings software engineering discipline to data transformations:
1. Version Control Everything
- SQL transformations stored in Git repositories
- Complete history of changes and who made them
- Branch-based development workflows
- Code review processes for data transformations
2. Automated Testing
- Schema tests: Ensure data quality and consistency
- Data tests: Validate business rules and constraints
- Freshness tests: Monitor data pipeline health
- Custom tests: Business-specific validation rules
3. Documentation as Code
- Automated documentation generation
- Column-level descriptions and business context
- Data lineage visualization
- Self-updating documentation with code changes
4. Modular Development
- Reusable macros and models
- DRY (Don't Repeat Yourself) principles
- Dependency management between models
- Incremental processing for large datasets
Snowflake: The Modern Data Warehouse
Snowflake provides the perfect foundation for dbt:
1. Performance and Scalability
- Automatic scaling based on workload
- Separate compute and storage resources
- Multi-cluster warehouses for concurrent workloads
- Zero-copy cloning for development environments
2. Developer Experience
- SQL-native interface that data teams understand
- Time travel for data recovery and testing
- Instant provisioning of compute resources
- Native support for semi-structured data
3. Security and Governance
- Role-based access control
- Data encryption at rest and in transit
- Audit logging and monitoring
- Compliance certifications (SOC 2, GDPR, HIPAA)
Implementing CI/CD for Data Pipelines
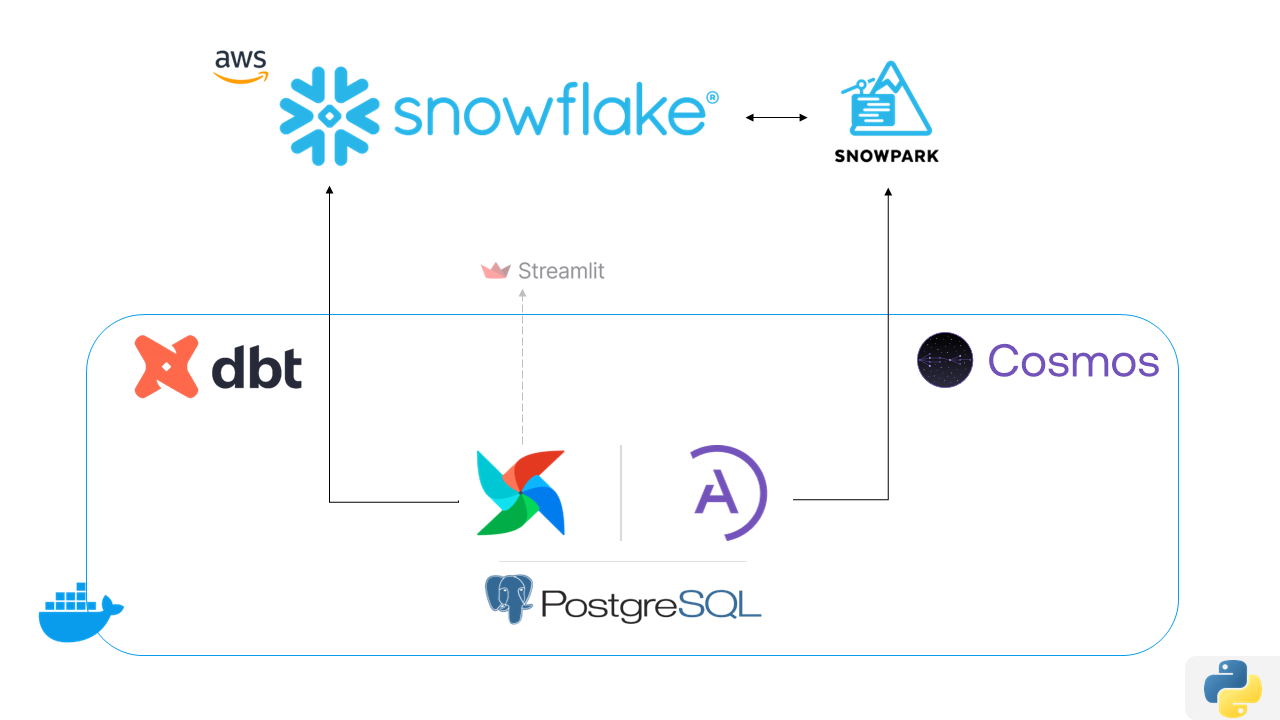
Our CI/CD Architecture
Development Workflow:
- Feature Branch Creation: Developers create branches for new features
- Local Development: Test transformations locally using dbt
- Pull Request: Submit changes for code review
- Automated Testing: CI pipeline runs comprehensive tests
- Staging Deployment: Deploy to staging environment
- Production Deployment: Automated deployment after approval
CI/CD Pipeline Components
1. Source Control Integration
Git Repository Structure:
- models/ - dbt models (SQL transformations)
- macros/ - Reusable SQL macros
- tests/ - Custom data tests
- docs/ - Documentation
- profiles/ - Environment configurations
- .github/workflows/ - CI/CD pipeline definitions
2. Automated Testing Framework
| Test Type | Purpose | Example |
|---|---|---|
| Unit Tests | Test individual model logic | Validate calculation accuracy |
| Integration Tests | Test model dependencies | Ensure upstream/downstream consistency |
| Data Quality Tests | Validate business rules | Check for null values, duplicates |
| Performance Tests | Monitor query performance | Identify slow-running transformations |
| Regression Tests | Prevent breaking changes | Compare outputs before/after changes |
3. Environment Management
Development Environment:
- Individual developer sandboxes
- Full copy of production data (anonymized)
- Rapid iteration and experimentation
- No impact on production systems
Staging Environment:
- Production-like environment for testing
- Automated deployment from main branch
- Integration testing with downstream systems
- Performance and load testing
Production Environment:
- Fully automated deployments
- Blue-green deployment strategy
- Automated rollback capabilities
- Comprehensive monitoring and alerting
Implementation Best Practices
1. Code Organization and Standards
Model Naming Conventions:
- Staging models: stg_[source]_[entity] (e.g., stg_salesforce_accounts)
- Intermediate models: int_[entity]_[transformation] (e.g., int_customers_aggregated)
- Mart models: dim_[entity] or fct_[event] (e.g., dim_customers, fct_sales)
SQL Style Guide:
- Consistent formatting and indentation
- Meaningful column aliases
- Comprehensive commenting
- Modular, reusable code structures
2. Testing Strategy
Schema Tests (Built-in dbt tests):
Example schema.yml configuration:
- Test customer_id for uniqueness and not_null values
- Test email for uniqueness and not_null values
- Configure column-level data quality checks
Custom Business Logic Tests:
Example business rule validation:
- Create tests to ensure revenue values are positive
- Validate business logic and constraints
- Check for data consistency across models
Data Freshness Tests:
Example freshness monitoring:
- Configure warnings after 12 hours without updates
- Set errors after 24 hours of stale data
- Monitor data pipeline health automatically
3. Deployment Strategies
Blue-Green Deployment:
- Maintain two identical production environments
- Deploy to inactive environment first
- Switch traffic after validation
- Instant rollback capability
Incremental Deployment:
- Deploy changes to subset of data first
- Gradually increase deployment scope
- Monitor performance and data quality
- Full rollout after validation
Monitoring and Observability
Key Metrics to Track
Pipeline Health Metrics:
| Metric | Description | Alert Threshold |
|---|---|---|
| Test Success Rate | Percentage of tests passing | < 95% |
| Pipeline Runtime | Total execution time | > 2x baseline |
| Data Freshness | Time since last update | > 4 hours |
| Row Count Changes | Unexpected data volume changes | > 20% variance |
| Cost per Pipeline | Snowflake compute costs | > Budget threshold |
Business Impact Metrics:
- Data Quality Score: Overall data reliability
- Time to Production: Development velocity
- Mean Time to Recovery: Incident response effectiveness
- User Satisfaction: Data consumer feedback
Alerting and Incident Response
Automated Alerting:
- Slack/Teams Integration: Real-time notifications
- Email Alerts: Critical failure notifications
- Dashboard Monitoring: Visual pipeline health status
- PagerDuty Integration: On-call incident management
Incident Response Process:
- Detection: Automated monitoring identifies issues
- Assessment: Determine impact and severity
- Response: Execute rollback or hotfix procedures
- Resolution: Implement permanent fix
- Post-Mortem: Document lessons learned
Advanced CI/CD Patterns
1. Feature Flags for Data
Conditional Logic in dbt:
Feature flags enable safe deployment of new transformation logic:
- Use conditional statements to switch between old and new logic
- Enable gradual rollout of new segmentation algorithms
- Maintain backward compatibility during transitions
Benefits:
- Safe deployment of new features
- A/B testing for transformation logic
- Gradual rollout capabilities
- Easy rollback without code changes
2. Data Contracts and Schema Evolution
Schema Validation:
Implement automated schema validation to ensure data contracts:
- Validate that upstream data meets expected schema requirements
- Use pre-hooks to check data structure before processing
- Prevent breaking changes from propagating downstream
Breaking Change Detection:
- Automated schema comparison
- Impact analysis for downstream dependencies
- Notification to affected teams
- Migration assistance tools
3. Cross-Environment Data Validation
Production vs. Staging Comparison:
Implement cross-environment validation to ensure deployment quality:
- Compare row counts and key metrics between environments
- Calculate differences in revenue totals and other critical measures
- Automated validation before production deployment
- Alert on significant variances that might indicate issues
Cost Optimization Strategies
Snowflake Cost Management
Compute Optimization:
- Auto-suspend warehouses: Prevent idle compute costs
- Right-size warehouses: Match compute to workload requirements
- Query optimization: Improve performance and reduce costs
- Clustering keys: Optimize large table performance
Storage Optimization:
- Data lifecycle policies: Archive old data automatically
- Compression strategies: Reduce storage footprint
- Zero-copy cloning: Efficient environment provisioning
- Time travel settings: Balance recovery needs with costs
dbt Performance Optimization
Model Materialization Strategies:
| Strategy | Use Case | Performance | Cost |
|---|---|---|---|
| Table | Frequently queried, stable data | Fast reads | Higher storage |
| View | Infrequently queried, dynamic data | Slower reads | Lower storage |
| Incremental | Large, append-only datasets | Fast builds | Optimal balance |
| Ephemeral | Intermediate transformations | N/A | Lowest cost |
Incremental Model Example:
Configure incremental processing for large datasets:
- Set materialization to incremental with unique key
- Process only new records since last run
- Optimize for append-only datasets
- Reduce processing time and compute costs
Team Collaboration and Governance
Development Workflow
1. Feature Development Process:
- Create feature branch from main
- Develop and test locally
- Submit pull request with comprehensive description
- Peer review focusing on logic, performance, and standards
- Automated testing validation
- Merge after approval
2. Code Review Standards:
- Logic Review: Validate business requirements
- Performance Review: Identify optimization opportunities
- Style Review: Ensure coding standards compliance
- Documentation Review: Verify adequate documentation
Data Governance Framework
1. Data Quality Standards:
- Mandatory tests for critical business metrics
- Data freshness requirements by dataset
- Acceptable data quality thresholds
- Escalation procedures for quality issues
2. Access Control:
- Role-based permissions in Snowflake
- Environment-specific access controls
- Audit logging for all data access
- Regular access review processes
3. Documentation Requirements:
- Model-level business context
- Column-level descriptions
- Data lineage documentation
- Business glossary maintenance
Measuring Success
Key Performance Indicators
Development Velocity:
- Deployment Frequency: How often we deploy to production
- Lead Time: Time from code commit to production deployment
- Change Failure Rate: Percentage of deployments causing issues
- Mean Time to Recovery: Time to resolve production incidents
Data Quality Metrics:
- Test Coverage: Percentage of models with adequate testing
- Test Success Rate: Percentage of tests passing consistently
- Data Freshness: Timeliness of data availability
- Accuracy Score: Correctness of business calculations
Business Impact:
- User Adoption: Growth in data platform usage
- Self-Service Capability: Reduction in ad-hoc data requests
- Decision Speed: Faster access to trusted data
- Cost Efficiency: Optimized compute and storage costs
Common Challenges and Solutions
Challenge 1: Legacy System Integration
Problem: Integrating with legacy systems that don't support modern APIs
Solutions:
- Implement change data capture (CDC) for real-time updates
- Use batch processing with proper error handling
- Create abstraction layers to isolate legacy system complexity
- Gradual migration strategy with parallel processing
Challenge 2: Data Quality at Scale
Problem: Maintaining data quality as data volume and complexity grows
Solutions:
- Implement comprehensive testing at multiple levels
- Use statistical process control for anomaly detection
- Automate data profiling and quality monitoring
- Establish data contracts with upstream systems
Challenge 3: Performance Optimization
Problem: Slow-running transformations impacting SLAs
Solutions:
- Implement incremental processing strategies
- Optimize SQL queries and use appropriate materialization
- Leverage Snowflake clustering and partitioning
- Monitor and tune warehouse sizing
Challenge 4: Team Scaling
Problem: Maintaining code quality as the team grows
Solutions:
- Establish clear coding standards and review processes
- Implement automated testing and quality gates
- Create comprehensive documentation and training materials
- Use pair programming for knowledge transfer
Future Trends and Innovations
Emerging Technologies
1. Machine Learning Integration:
- ML-powered data quality monitoring: Automatic anomaly detection
- Intelligent query optimization: AI-driven performance tuning
- Predictive data freshness: Anticipate and prevent data delays
- Automated root cause analysis: Faster incident resolution
2. Real-time Processing:
- Streaming transformations: Process data as it arrives
- Event-driven architectures: React to data changes immediately
- Micro-batch processing: Balance latency and efficiency
- Real-time data quality monitoring: Immediate feedback loops
3. Advanced Automation:
- Self-healing pipelines: Automatic recovery from common failures
- Intelligent scaling: Dynamic resource allocation based on workload
- Automated testing generation: AI-generated test cases
- Smart deployment strategies: Context-aware deployment decisions
Conclusion
Implementing software engineering discipline in data engineering through dbt and Snowflake CI/CD represents a fundamental shift in how we approach data transformation and delivery. This approach brings the reliability, scalability, and maintainability that software engineering teams have enjoyed for decades to the data domain.
The key to success lies in treating data transformations as first-class software products, complete with version control, automated testing, continuous integration, and robust deployment processes. Organizations that embrace these practices will build more reliable data platforms, deliver higher quality insights, and enable faster, more confident decision-making.
As we continue to evolve our data engineering practices in 2025, the combination of dbt's transformation capabilities, Snowflake's cloud-native architecture, and modern CI/CD practices provides a powerful foundation for building the data platforms of the future.
The investment in these practices pays dividends through improved data quality, faster development cycles, reduced operational overhead, and most importantly, increased trust in the data that drives critical business decisions.
Tags
UpthriveAI Team
Our expert team at UpthriveAI specializes in data warehousing, AI/ML solutions, and cloud technologies. We help organizations transform their data into actionable insights and competitive advantages.
Get in TouchRelated Articles

Let's Discuss Your Data Journey
Ready to unlock the full potential of your data? Our experts are here to help you design and implement the perfect solution for your business needs.
What to Expect
- Free initial consultation and data assessment
- Custom solution design tailored to your needs
- Transparent pricing with no hidden costs
Our team typically responds to inquiries within 4 hours during business hours.
What you'll get:
- Weekly data engineering insights and tutorials
- Latest AI and machine learning trends
- Industry case studies and best practices
- Early access to our blog posts and resources